If you plan on being a Linux admin, you’re going to need to understand regular expressions. Start that journey here.

Image: Getty Images/iStockphoto
If you’re new to the world of Linux administration and open source software, you’ve probably only just started scratching the surface of the power this new world offers. Eventually, however, you’ll start mining deeper depths. When that fateful moment arrives, chances are you’re going to need to use a regular expression or two.
For the uninitiated, that can be a bit daunting. Say, for instance, you run into this:
/^[a-z0-9_-]{3,16}$/
What does that bit of cryptic nonsense mean? Well, it’s actually not nonsense. The above regular expression searches for a string of characters (/^ marks the beginning of the string and $/ marks the end), between three and 16 characters, that includes lowercase letters, the numbers 0-9, or an underscore or hyphen.
Every regular expression has meaning and use. Although they might seem a bit complicated for new users, it’s important to understand how they work.
Let’s take a crash course in learning how to compose a regular expression.
SEE: How smart tech is transforming the transportation industry (TechRepublic Premium)
What are regular expressions?
Simply put, regular expressions, or regex, use letters and symbols to define patterns to find matching character sequences in a file or data stream. Regular expressions are a language unto themselves and can be simple or highly complex. Regular expressions can be used in commands, in bash scripts, and even within GUI applications.
What we’re going to do is create a file and then use regular expressions to search that file for strings of characters. The file we’ll create will contain a collection of names and email addresses (fake, of course). We’ll then craft regular expressions to search through that file.
Create the new file with the command:
nano email-list.txt
Paste the following into that file:
Tock tock@fakedomain.com Vega vega@notadomain.com Jo St. Claire jo@domainnotreal.com Wil Jackson wil@sonotreal.com Miguel Santos miguel@stillsofake.com Ashley Tate ashley@localhost.com Olivia Nightingale olivia@example.com Nathan Gage nathan@mydomain.com Bethany Nitshimi bethany@yesthisisfake.com Jessie Blake jessie@notevenreal.net Ralph Moore ralph@trashdomain.net Tim Tomas tim@blahblahblah.net Tom James tom@regexisfun.net
Save and close the file.
Now, let’s do some searching.
How to search for repeated characters
For our example, we’re going to be employing the egrep tool (which is the same as “grep -E”). The egrep command is quite powerful and easy to use. Say, for example, you don’t remember Jessie Blake’s email address, but you remember the name. You could issue the command:
egrep "Jessie Blake" email-list.txt
That would print out the line containing “Jessie Blake,” which would include the email address. But what if you couldn’t remember Jessie’s name, but knew (for whatever reason) there was a single “ss” string in the name? You could use egrep and a regular expression to search for that string.
To search for repeated characters, you employ the {x} string (where x is the number of repetition). Since we’re searching for the s character repeated twice, that would look like:
s{2}
So we employ this with egrep like so:
egrep 's{2}' email-list.txt
The output would display the same results as the original grep command, only highlighting the two repeated “s” characters (Figure A).
Figure A
” data-credit rel=”noopener noreferrer nofollow”>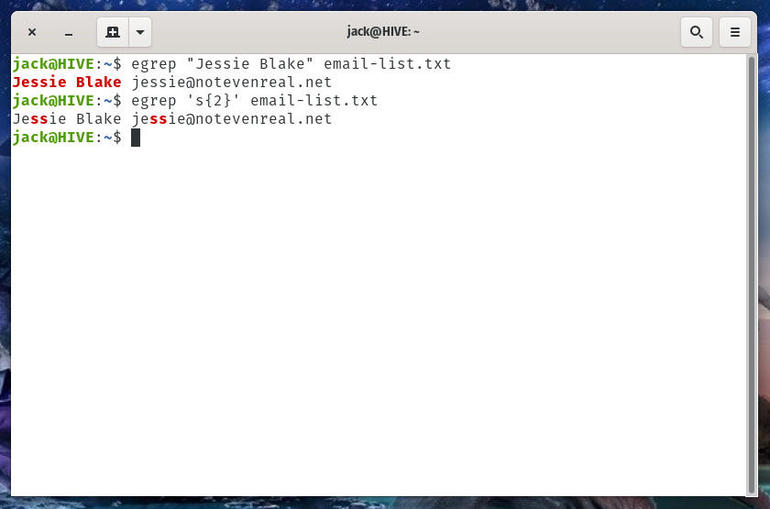
Repeated “s” characters found with egrep.
The regular expression in the above command is ‘s{2}’
Let’s use that same regular expression and make it a bit more complicated. Say you’re looking for the name that includes “ess.” You have one instance of e and two instances of s. How do you use the same type of regular expression as you did before, but search for that string? That regular expression would look like:
es{1,2}
So now our egrep command looks like:
egrep 'es{1,2}' email-list.txt
An even more complicated twist on this is to search for all sequences of two or more vowels. This would reveal strings like ai, ue, ey, ia, ea, and ie.
To do this, we’ll employ the [ ] and the { }. The [ ] will encase our vowels to indicate we’re searching for any combination of the characters contained within. Since we’re searching for two or more vowels, we’ll use {2,}. Because we don’t indicate the second numerical value, we leave it open ended.
For this, our regular expression will be:
'[aeiouy]{2,}'
The egrep command using that string is:
egrep '[aeiouy]{2,}' email-list.txt
The results will highlight the discovered strings (Figure B).
Figure B
” data-credit rel=”noopener noreferrer nofollow”>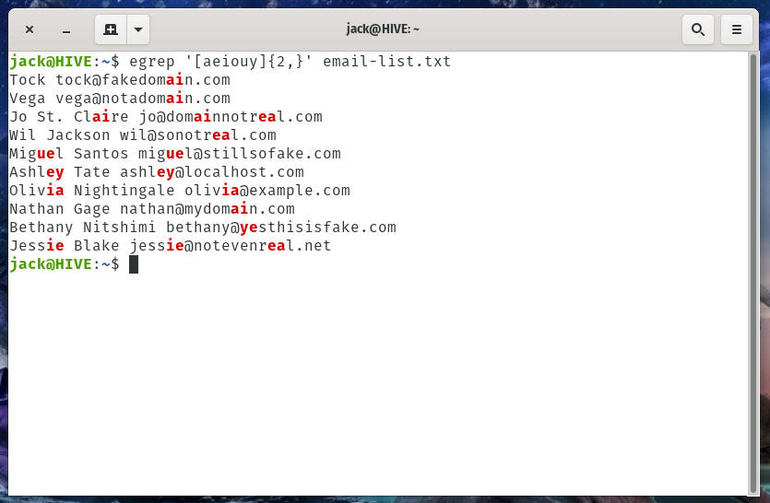
Our regular expression does include y as a vowel.
Or what if we want email addresses and last names of anyone in the list with the first names Tim and Tom? That’s possible as well, with the help of our [aeiouy] regular expression. With the help of egrep, we issue the command:
egrep 'T[aeiou]m' email-list.txt
The command will catch both Tim and Tom in Tim Tomas and Tom James (Figure C).
Figure C
” data-credit rel=”noopener noreferrer nofollow”>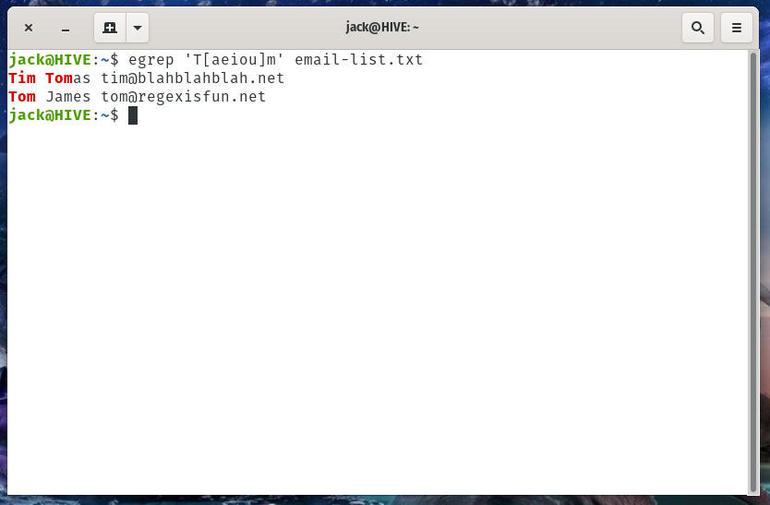
Tim and Tom are found.
Notice, however, that regex doesn’t catch “tim” and “tom” in the email addresses. Why? Because regex is case sensitive. To overcome that, we’d have to add another piece to the regular expression like so:
egrep '[Tt][aeiou]m' email-list.txt
As you can see, what we’ve done here is indicate that we’re searching for a string that starts with either T or t, has any combination of vowels, and ends with m. The output would then highlight the email addresses as well (Figure D).
Figure D
” data-credit rel=”noopener noreferrer nofollow”>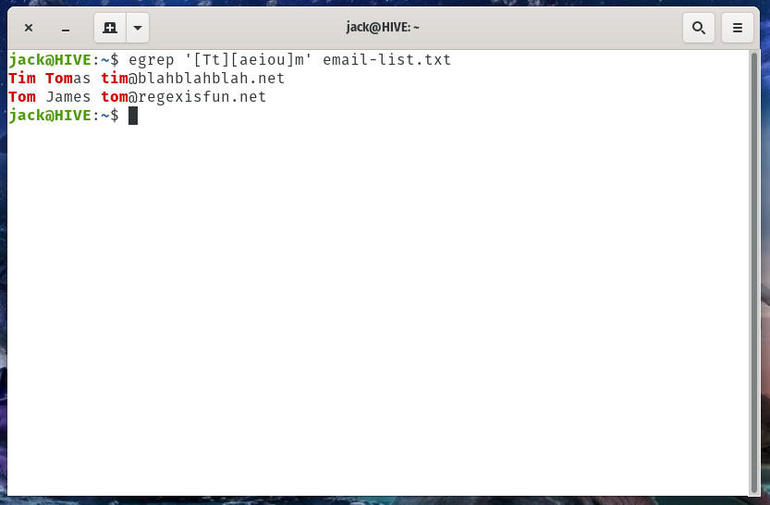
Tim and Tom and tim and tom found with regex.
And that’s the beginning of your journey with regex. We’ll continue this journey later on, and build on what we’ve learned so far. However, you should be able to use what you’ve learned here and work it into your bash scripts and commands.

Open Source Weekly Newsletter
You don’t want to miss our tips, tutorials, and commentary on the Linux OS and open source applications. Delivered Tuesdays
Also see
Source of Article



