While some assistance is available to individuals who lack the power of speech, verbally communicating with other people can still be challenging. A new face-worn strain sensor could help, as it’s able to “read” the wearer’s silently mouthed words.
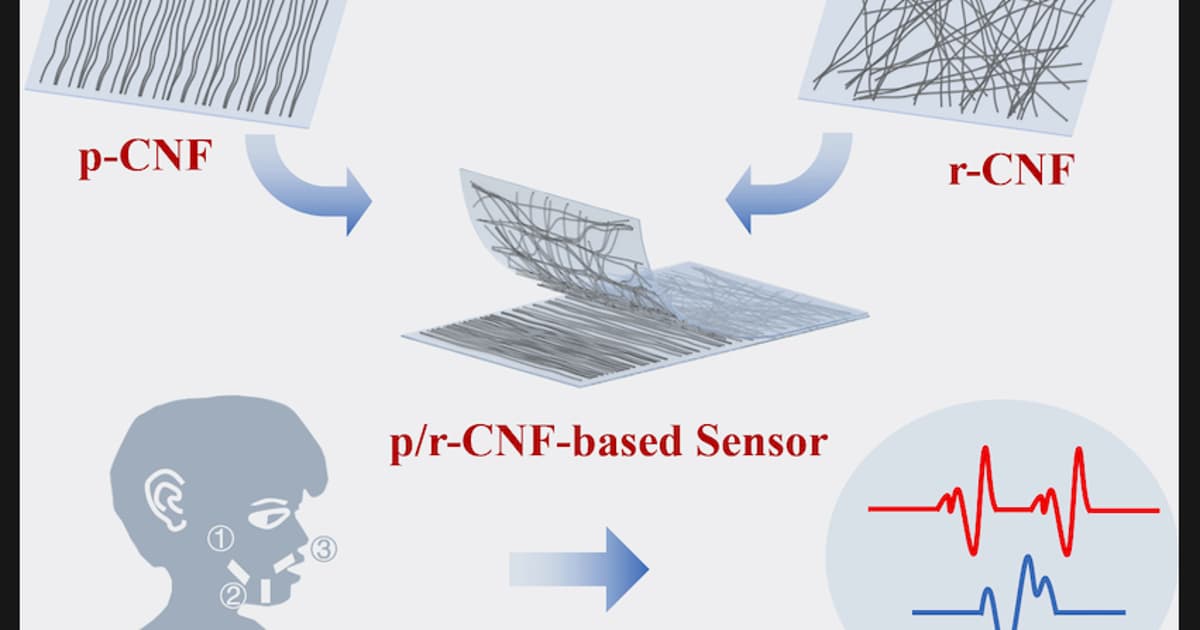
Developed at China’s Tsinghua University, the flexible, stretchable sensor takes the form of a thin elastomer substrate with two carbon-nanofiber membranes stacked on top. Multiple such sensors get temporarily adhered to the skin around the user’s lips and jaw.
The nanofibers in one membrane are aligned parallel to one another, allowing them to be highly sensitive to even the smallest of vibrations in the underlying skin. Strain sensors which solely incorporate nanofibers arranged in this fashion typically don’t perform well when stretched to a large extent, however, as their conductivity drops accordingly.
For that reason, the carbon nanofibers in the other membrane are randomly aligned. Although they’re not as sensitive as the parallel-aligned nanofibers, they do still function even when the membrane is stretched to its maximum limit, since they retain their conductivity.
As a result, by combining high sensitivity with a wide working range, the Tsinghua sensor is claimed to outperform similar experimental devices.
In a proof-of-concept exercise, several of the sensors were applied to a volunteer’s face, then connected to an Arduino microcomputer and a speaker. A machine-learning-based algorithm on the Arduino was able to accurately identify different phonetic sounds that the wearer was silently mouthing, based on the strain produced by their mouth movements. Those sounds were then synthetically relayed through the speaker.
The sensors were additionally able to accurately gauge the test subject’s facial expressions, eye movements, and pulse. That said, the technology needs to be developed further before it’s suitable for real-world everyday use.
“We will build out application scenarios of the lip-language recognition system, and improve the comfort and portability of wearing,” said the lead scientist, Peng Bi. “We hope that such a wearable device can become a second mouth for people with vocal cord damage, and mitigate the effect of this type of injury on someone’s daily life.”
A paper on the study was recently published in the journal Nano Research.
As a side note, Bi’s team isn’t the only group developing wearable silent-speech-reading systems. Cornell University’s Speechin necklace does the job via an upward-facing camera, while New York’s University at Buffalo’s EarCommand tech uses earbuds that monitor deformations of the ear canal.
Source: Tsinghua University Press via EurekAlert
Source of Article
