In this report, we look at the data generated by the O’Reilly online learning platform to discern trends in the technology industry—trends technology leaders need to follow.
But what are “trends”? All too often, trends degenerate into horse races over languages and platforms. Look at all the angst heating up social media when TIOBE or RedMonk releases their reports on language rankings. Those reports are valuable, but their value isn’t in knowing what languages are popular in any given month. And that’s what I’d like to get to here: the real trends that aren’t reflected (or at best, are indirectly reflected) by the horse races. Sometimes they’re only apparent if you look carefully at the data; sometimes it’s just a matter of keeping your ear to the ground.

Learn faster. Dig deeper. See farther.
In either case, there’s a difference between “trends” and “trendy.” Trendy, fashionable things are often a flash in the pan, forgotten or regretted a year or two later (like Pet Rocks or Chia Pets). Real trends unfold on much longer time scales and may take several steps backward during the process: civil rights, for example. Something is happening and, over the long arc of history, it’s not going to stop. In our industry, cloud computing might be a good example.
Methodology
This study is based on title usage on O’Reilly online learning. The data includes all usage of our platform, not just content that O’Reilly has published, and certainly not just books. We’ve explored usage across all publishing partners and learning modes, from live training courses and online events to interactive functionality provided by Katacoda and Jupyter notebooks. We’ve included search data in the graphs, although we have avoided using search data in our analysis. Search data is distorted by how quickly customers find what they want: if they don’t succeed, they may try a similar search with many of the same terms. (But don’t even think of searching for R or C!) Usage data shows what content our members actually use, though we admit it has its own problems: usage is biased by the content that’s available, and there’s no data for topics that are so new that content hasn’t been developed.
We haven’t combined data from multiple terms. Because we’re doing simple pattern matching against titles, usage for “AWS security” is a subset of the usage for “security.” We made a (very) few exceptions, usually when there are two different ways to search for the same concept. For example, we combined “SRE” with “site reliability engineering,” and “object oriented” with “object-oriented.”
The results are, of course, biased by the makeup of the user population of O’Reilly online learning itself. Our members are a mix of individuals (professionals, students, hobbyists) and corporate users (employees of a company with a corporate account). We suspect that the latter group is somewhat more conservative than the former. In practice, this means that we may have less meaningful data on the latest JavaScript frameworks or the newest programming languages. New frameworks appear every day (literally), and our corporate clients won’t suddenly tell their staff to reimplement the ecommerce site just because last year’s hot framework is no longer fashionable.
Usage and query data for each group are normalized to the highest value in each group. Practically, this means that you can compare topics within a group, but you can’t compare the groups with each other. Year-over-year (YOY) growth compares January through September 2020 with the same months of 2019. Small fluctuations (under 5% or so) are likely to be noise rather than a sign of a real trend.
Enough preliminaries. Let’s look at the data, starting at the highest level: O’Reilly online learning itself.
O’Reilly Online Learning
Usage of O’Reilly online learning grew steadily in 2020, with 24% growth since 2019. That may not be surprising, given the COVID-19 pandemic and the resulting changes in the technology industry. Companies that once resisted working from home were suddenly shutting down their offices and asking their staff to work remotely. Many have said that remote work will remain an option indefinitely. COVID had a significant effect on training: in-person training (whether on- or off-site) was no longer an option, so organizations of all sizes increased their participation in live online training, which grew by 96%. More traditional modes also saw increases: usage of books increased by 11%, while videos were up 24%. We also added two new learning modes, Katacoda scenarios and Jupyter notebooks, during the year; we don’t yet have enough data to see how they’re trending.
It’s important to place our growth data in this context. We frequently say that 10% growth in a topic is “healthy,” and we’ll stand by that, but remember that O’Reilly online learning itself showed 24% growth. So while a technology whose usage is growing 10% annually is healthy, it’s not keeping up with the platform.
As travel ground to a halt, so did traditional in-person conferences. We closed our conference business in March, replacing it with live virtual Superstreams. While we can’t compare in-person conference data with virtual event data, we can make a few observations. The most successful superstream series focused on software architecture and infrastructure and operations. Why? The in-person O’Reilly Software Architecture Conference was small but growing. But when the pandemic hit, companies found out that they really were online businesses—and if they weren’t, they had to become online to survive. Even small restaurants and farm markets were adding online ordering features to their websites. Suddenly, the ability to design, build, and operate applications at scale wasn’t optional; it was necessary for survival.
Programming Languages
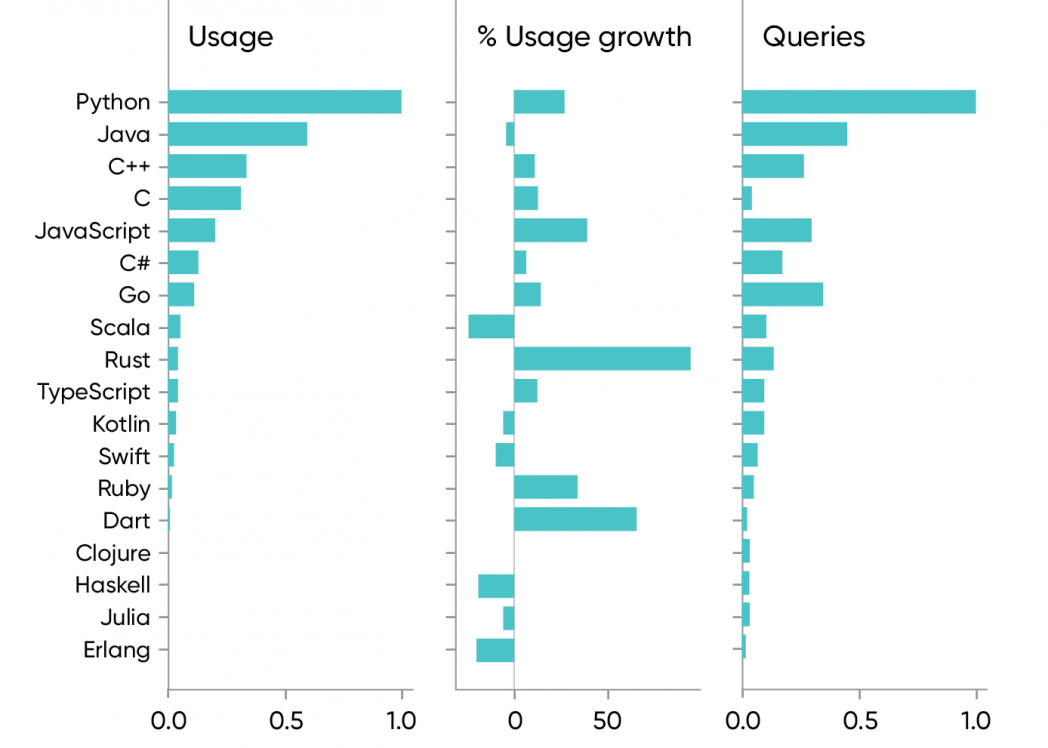
Although we’re not fans of the language horse race, programming languages are as good a place as any to start. Figure 1 shows usage, year-over-year growth in usage, and the number of search queries for several popular languages. The top languages for O’Reilly online learning are Python (up 27%), Java (down 3%), C++ (up 10%), C (up 12%), and JavaScript (up 40%). Looking at 2020 usage rather than year-over-year changes, it’s surprising to see JavaScript so far behind Python and Java. (JavaScript usage is 20% of Python’s, and 33% of Java’s.)
Past the top five languages, we see healthy growth in Go (16%) and Rust (94%). Although we believe that Rust’s popularity will continue to grow, don’t get too excited; it’s easy to grow 94% when you’re starting from a small base. Go has clearly established itself, particularly as a language for concurrent programming, and Rust is likely to establish itself for “system programming”: building new operating systems and tooling for cloud operations. Julia, a language designed for mathematical computation, is an interesting wild card. It’s slightly down over the past year, but we’re optimistic about its long term chances.
We shouldn’t separate usage of titles specifically aimed at learning a programming language from titles applying the language or using frameworks based on it. After all, many Java developers use Spring, and searching for “Java” misses content only has the word “Spring” in the title. The same is true for JavaScript, with the React, Angular, and Node.js frameworks. With Python, the most heavily used libraries are PyTorch and scikit-learn. Figure 2 shows what happens when you add the use of content about Python, Java, and JavaScript to the most important frameworks for those languages.
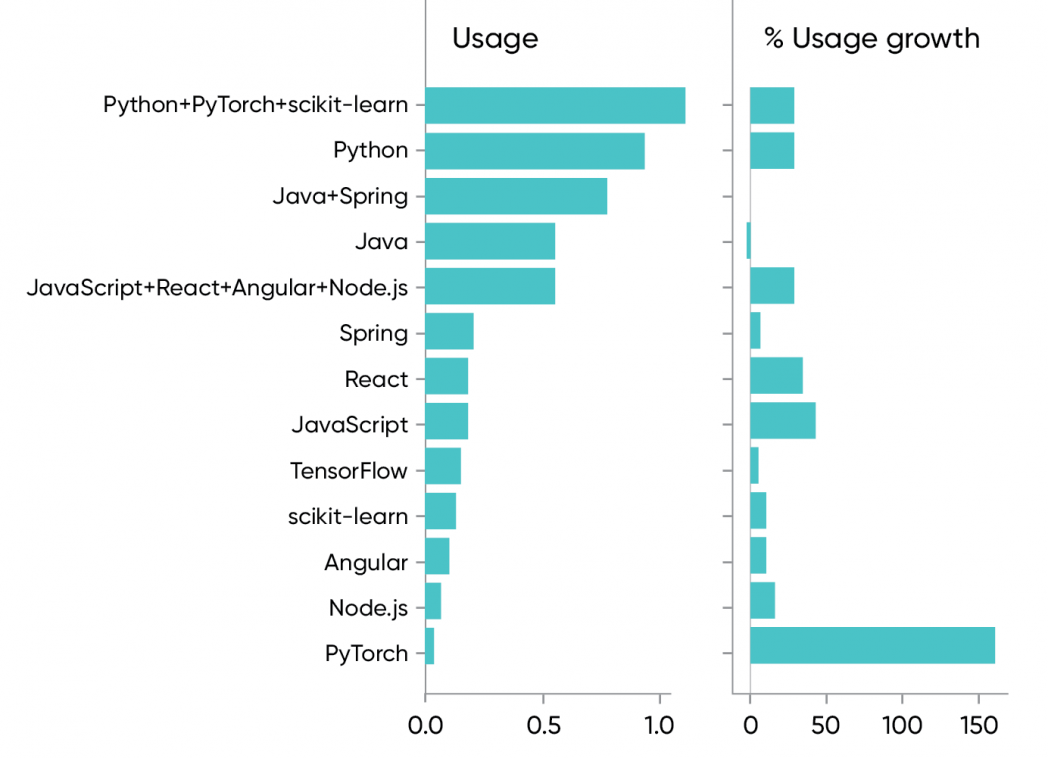
It probably isn’t a surprise that the results are similar, but there are some key differences. Adding usage and search query data for Spring (up 7%) reverses Java’s apparent decline (net-zero growth). Zero growth isn’t inappropriate for an established enterprise language, particularly one owned by a company that has mired the language in controversy. Looking further at JavaScript, if you add in usage for the most popular frameworks (React, Angular, and Node.js), JavaScript usage on O’Reilly online learning rises to 50% of Python’s, only slightly behind Java and its frameworks. However, Python, when added to the heavily used frameworks PyTorch and scikit-learn, remains the clear leader.
It’s important to understand what we’ve done though. We’re trying to build a more comprehensive picture of language use that includes the use of various frameworks. We’re not pretending the frameworks themselves are comparable—Spring is primarily for backend and middleware development (though it includes a web framework); React and Angular are for frontend development; and scikit-learn and PyTorch are machine learning libraries. And although it’s widely used, we didn’t assign TensorFlow to any language; it has bindings for Python, Java, C++, and JavaScript, and it’s not clear which language predominates. (Google Trends suggests C++.) We also ignored thousands (literally) of minor platforms, frameworks, and libraries for all these languages; once you get past the top few, you’re into the noise.
We aren’t advocating for Python, Java, or any other language. None of these top languages are going away, though their stock may rise or fall as fashions change and the software industry evolves. We’re just saying that when you make comparisons, you have to be careful about exactly what you’re comparing. The horse race? That’s just what it is. Fun to watch, and have a mint julep when it’s over, but don’t bet your savings (or your job) on it.
If the horse race isn’t significant, just what are the important trends for programming languages? We see several factors changing pro‐ gramming in significant ways:
- Multiparadigm languages
Since last year, O’Reilly online learning has seen a 14% increase in the use of content on functional programming. However, Haskell and Erlang, the classic functional languages, aren’t where the action is; neither shows significant usage, and both are headed down (roughly 20% decline year over year). Object oriented programming is up even more than functional programming: 29% growth since last year. This suggests that the real story is the integration of functional features into procedural and object-oriented languages. Starting with Python 3.0 in 2008 and continuing with Java 8 in 2014, programming languages have added higher-order functions (lambdas) and other “functional” features. Several popular languages (including JavaScript and Go) have had functional features from the beginning. This trend started over 20 years ago (with the Standard Template Library for C++), and we expect it to continue. - Concurrent programming
Platform data for concurrency shows an 8% year-over-year increase. This isn’t a large number, but don’t miss the story because the numbers are small. Java was the first widely used language to support concurrency as part of the language. In the mid-’90s, thread support was a luxury; Moore’s law had plenty of room to grow. That’s no longer the case, and support for concurrency, like support for functional programming, has become table stakes. Go, Rust, and most other modern languages have built-in support for concurrency. Concurrency has always been one of Python’s weaknesses. - Dynamic versus static typing
This is another important paradigmatic axis. The distinction between languages with dynamic typing (like Ruby and JavaScript) and statically typed languages (like Java and Go) is arguably more important than the distinction between functional and object-oriented languages. Not long ago, the idea of adding static typing to dynamic languages would have started a brawl. No longer. Combining paradigms to form a hybrid is taking a hold here too. Python 3.5 added type hinting, and more recent versions have added additional static typing features. TypeScript, which adds static typing to JavaScript, is coming into its own (12% year-over-year increase). - Low-code and no-code computing
It’s hard for a learning platform to gather data about a trend that minimizes the need to learn, but low-code is real and is bound to have an effect. Spreadsheets were the forerunner of low-code computing. When VisiCalc was first released in 1979, it enabled millions to do significant and important computation without learning a programming language. Democratization is an important trend in many areas of technology; it would be surprising if programming were any different.
What’s important isn’t the horse race so much as the features that languages are acquiring, and why. Given that we’ve run to the end of Moore’s law, concurrency will be central to the future of programming. We can’t just get faster processors. We’ll be working with microservices and serverless/functions-as-a-service in the cloud for a long time–and these are inherently concurrent systems. Functional programming doesn’t solve the problem of concurrency—but the discipline of immutability certainly helps avoid pitfalls. (And who doesn’t love first-class functions?) As software projects inevitably become larger and more complex, it makes eminent sense for languages to extend themselves by mixing in functional features. We need programmers who are thinking about how to use functional and object-oriented features together; what practices and patterns make sense when building enterprise-scale concurrent software?
Low-code and no-code programming will inevitably change the nature of programming and programming languages:
- There will be new languages, new libraries, and new tools to support no- or low-code programmers. They’ll be very simple. (Horrors, will they look like BASIC? Please no.) Whatever form they take, it will take programmers to build and maintain them.
- We’ll certainly see sophisticated computer-aided coding as an aid to experienced programmers. Whether that means “pair programming with a machine” or algorithms that can write simple programs on their own remains to be seen. These tools won’t eliminate programmers; they’ll make programmers more productive.
There will be a predictable backlash against letting the great unwashed into the programmers’ domain. Ignore it. Low-code is part of a democratization movement that puts the power of computing into more peoples’ hands, and that’s almost always a good thing. Programmers who realize what this movement means won’t be put out of jobs by nonprogrammers. They’ll be the ones becoming more productive and writing the tools that others will use.
Whether you’re a technology leader or a new programmer, pay attention to these slow, long-term trends. They’re the ones that will change the face of our industry.
Operations or DevOps or SRE
The science (or art) of IT operations has changed radically in the last decade. There’s been a lot of discussion about operations culture (the movement frequently known as DevOps), continuous integration and deployment (CI/CD), and site reliability engineering (SRE). Cloud computing has replaced data centers, colocation facilities, and in-house machine rooms. Containers allow much closer integration between developers and operations and do a lot to standardize deployment.
Operations isn’t going away; there’s no such thing as NoOps. Technologies like Function as a Service (a.k.a. FaaS, a.k.a. serverless, a.k.a. AWS Lambda) only change the nature of the beast. The number of people needed to manage an infrastructure of a given size has shrunk, but the infrastructures we’re building have expanded, sometimes by orders of magnitude. It’s easy to round up tens of thousands of nodes to train or deploy a complex AI application. Even if those machines are all in Amazon’s giant data centers and managed in bulk using highly automated tools, operations staff still need to keep systems running smoothly, monitoring, troubleshooting, and ensuring that you’re not paying for resources you don’t need. Serverless and other cloud technologies allow the same operations team to manage much larger infrastructures; they don’t make operations go away.
The terminology used to describe this job fluctuates, but we don’t see any real changes. The term “DevOps” has fallen on hard times. Usage of DevOps-titled content in O’Reilly online learning has dropped by 17% in the past year, while SRE (including “site reliability engineering”) has climbed by 37%, and the term “operations” is up 25%. While SRE and DevOps are distinct concepts, for many customers SRE is DevOps at Google scale–and who doesn’t want that kind of growth? Both SRE and DevOps emphasize similar practices: version control (62% growth for GitHub, and 48% for Git), testing (high usage, though no year-over-year growth), continuous deployment (down 20%), monitoring (up 9%), and observability (up 128%). Terraform, HashiCorp’s open source tool for automating the configuration of cloud infrastructure, also shows strong (53%) growth.
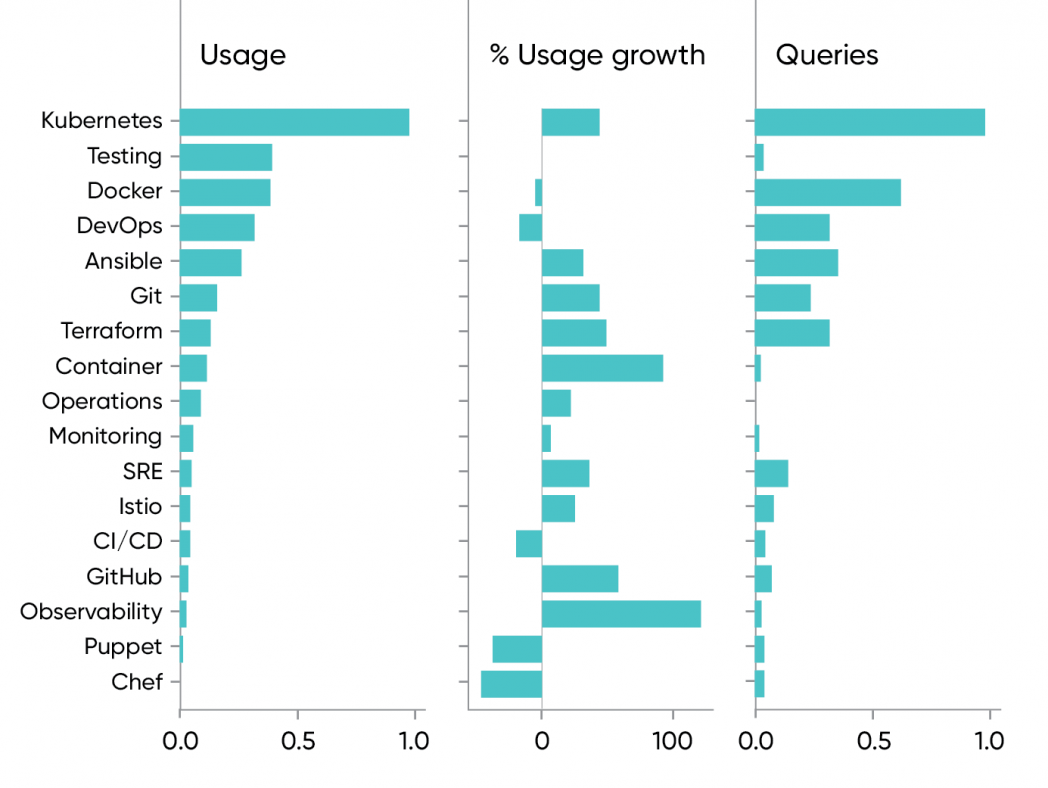
It’s more interesting to look at the story the data tells about the tools. Docker is close to flat (5% decline year over year), but usage of content about containers skyrocketed by 99%. So yes, containerization is clearly a big deal. Docker itself may have stalled—we’ll know more next year—but Kubernetes’s dominance as the tool for container orchestration keeps containers central. Docker was the enabling technology, but Kubernetes made it possible to deploy containers at scale.
Kubernetes itself is the other superstar, with 47% growth, along with the highest usage (and the most search queries) in this group. Kubernetes isn’t just an orchestration tool; it’s the cloud’s operating system (or, as Kelsey Hightower has said, “Kubernetes will be the Linux of distributed systems”). But the data doesn’t show the number of conversations we’ve had with people who think that Kubernetes is just “too complex.” We see three possible solutions:
- A “simplified” version of Kubernetes that isn’t as flexible, but trades off a lot of the complexity. K3s is a possible step in this direction. The question is, What’s the trade-off? Here’s my version of the Pareto principle, also known as the 80/20 rule. Given any system (like Kubernetes), it’s usually possible to build something simpler by keeping the most widely used 80% of the features and cutting the other 20%. And some applications will fit within the 80% of the features that were kept. But most applications (maybe 80% of them?) will require at least one of the features that were sacrificed to make the system simpler.
- An entirely new approach, some tool that isn’t yet on the horizon. We have no idea what that tool is. In Yeats’s words, “What rough beast…slouches towards Bethlehem to be born”?
- An integrated solution from a cloud vendor (for example, Microsoft’s open source Dapr distributed runtime). I don’t mean cloud vendors that provide Kubernetes as a service; we already have those. What if the cloud vendors integrate Kubernetes’s functionality into their stack in such a way that that functionality disappears into some kind of management console? Then the question becomes, What features do you lose, and do you need them? And what kind of vendor lock-in games do you want to play?
The rich ecosystem of tools surrounding Kubernetes (Istio, Helm, and others) shows how valuable it is. But where do we go from here? Even if Kubernetes is the right tool to manage the complexity of modern applications that run in the cloud, the desire for simpler solutions will eventually lead to higher-level abstractions. Will they be adequate?
Observability saw the greatest growth in the past year (128%), while monitoring is only up 9%. While observability is a richer, more powerful capability than monitoring—observability is the ability to find the information you need to analyze or debug software, while monitoring requires predicting in advance what data will be useful—we suspect that this shift is largely cosmetic. “Observability” risks becoming the new name for monitoring. And that’s unfortunate. If you think observability is merely a more fashionable term for monitoring, you’re missing its value. Complex systems running in the cloud will need true observability to be manageable.
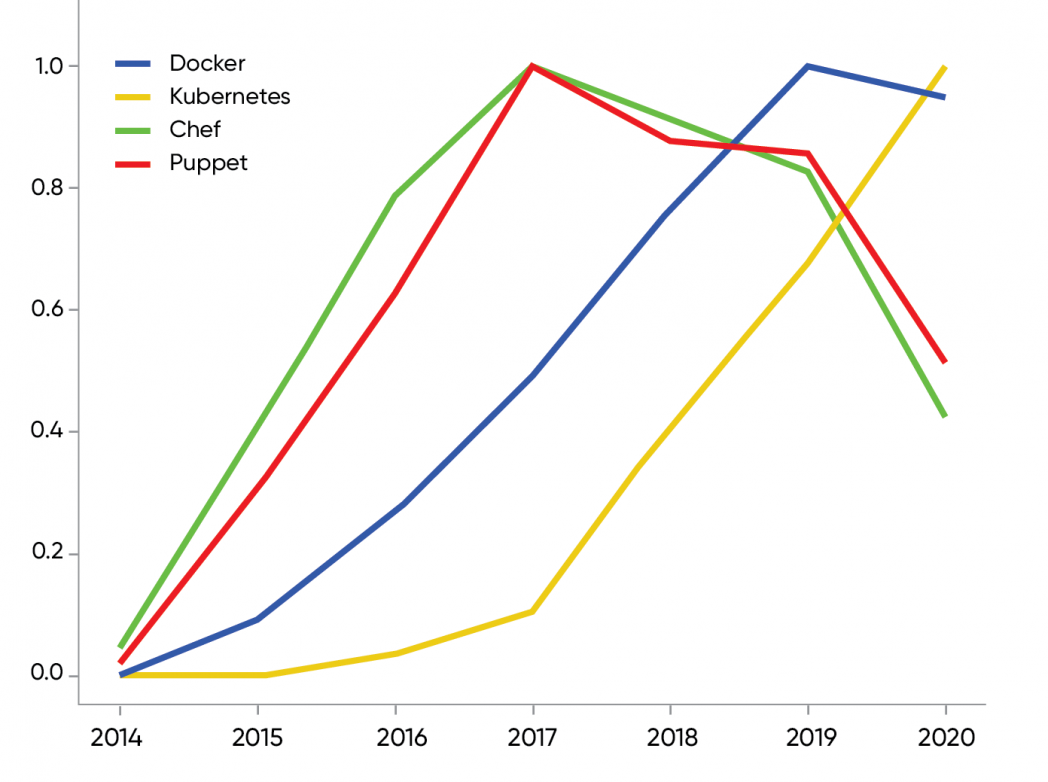
Infrastructure is code, and we’ve seen plenty of tools for automating configuration. But Chef and Puppet, two leaders in this movement, are both significantly down (49% and 40% respectively), as is Salt. Ansible is the only tool from this group that’s up (34%). Two trends are responsible for this. Ansible appears to have supplanted Chef and Puppet, possibly because Ansible is multilingual, while Chef and Puppet are tied to Ruby. Second, Docker and Kubernetes have changed the configuration game. Our data shows that Chef and Puppet peaked in 2017, when Kubernetes started an almost exponential growth spurt, as Figure 4 shows. (Each curve is normalized separately to 1; we wanted to emphasize the inflection points rather than compare usage.) Containerized deployment appears to minimize the problem of reproducible configuration, since a container is a complete software package. You have a container; you can deploy it many times, getting the same result each time. In reality, it’s never that simple, but it certainly looks that simple–and that apparent simplicity reduces the need for tools like Chef and Puppet.
The biggest challenge facing operations teams in the coming year, and the biggest challenge facing data engineers, will be learning how to deploy AI systems effectively. In the past decade, a lot of ideas and technologies have come out of the DevOps movement: the source repository as the single source of truth, rapid automated deployment, constant testing, and more. They’ve been very effective, but AI breaks the assumptions that lie behind them, and deployment is frequently the greatest barrier to AI success.
AI breaks these assumptions because data is more important than code. We don’t yet have adequate tools for versioning data (though DVC is a start). Models are neither code nor data, and we don’t have adequate tools for versioning models either (though tools like MLflow are a start). Frequent deployment assumes that the software can be built relatively quickly, but training a model can take days. It’s been suggested that model training doesn’t need to be part of the build process, but that’s really the most important part of the application. Testing is critical to continuous deployment, but the behavior of AI systems is probabilistic, not deterministic, so it’s harder to say that this test or that test failed. It’s particularly difficult if testing includes issues like fairness and bias.
Although there is a nascent MLOps movement, our data doesn’t show that people are using (or searching for) content in these areas in significant numbers. Usage is easily explainable; in many of these areas, content doesn’t exist yet. But users will search for content whether or not it exists, so the small number of searches shows that most of our users aren’t yet aware of the problem. Operations staff too frequently assume that an AI system is just another application—but they’re wrong. And AI developers too frequently assume that an operations team will be able to deploy their software, and they’ll be able to move on to the next project—but they’re also wrong. This situation is a train wreck in slow motion, and the big question is whether we can stop the trains before they crash. These problems will be solved eventually, with a new generation of tools—indeed, those tools are already being built—but we’re not there yet.
AI, Machine Learning, and Data
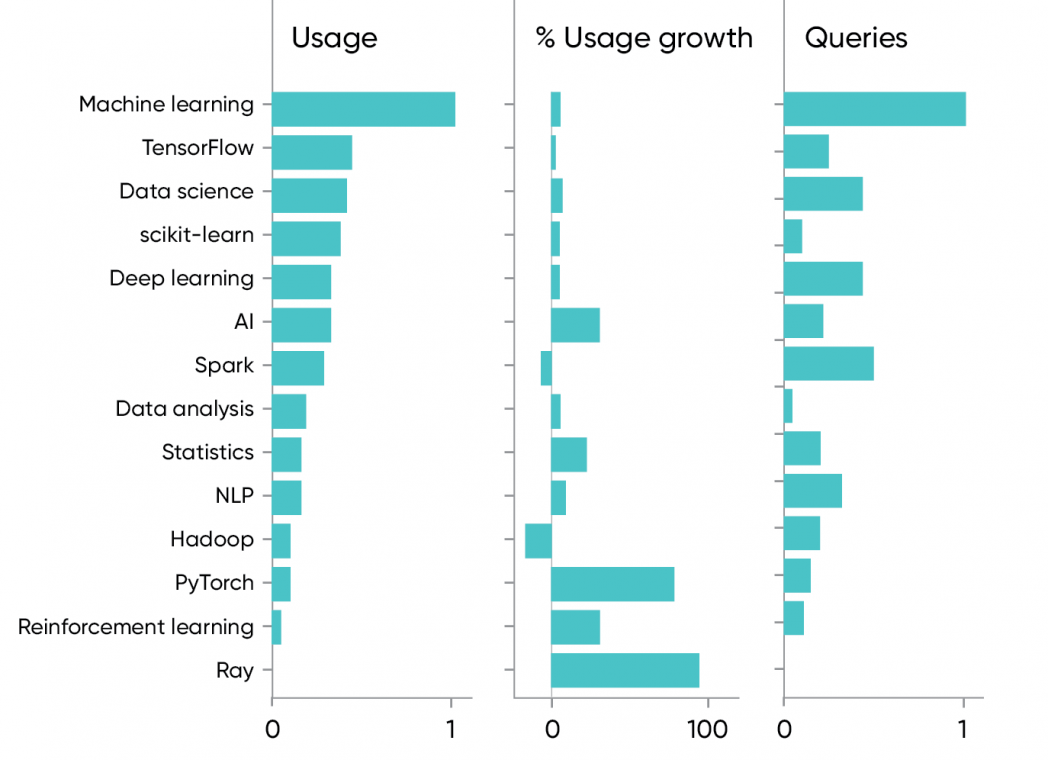
Healthy growth in artificial intelligence has continued: machine learning is up 14%, while AI is up 64%; data science is up 16%, and statistics is up 47%. While AI and machine learning are distinct concepts, there’s enough confusion about definitions that they’re frequently used interchangeably. We informally define machine learning as “the part of AI that works”; AI itself is more research oriented and aspirational. If you accept that definition, it’s not surprising that content about machine learning has seen the heaviest usage: it’s about taking research out of the lab and putting it into practice. It’s also not surprising that we see solid growth for AI, because that’s where bleeding-edge engineers are looking for new ideas to turn into machine learning.
Have the skepticism, fear, and criticism surrounding AI taken a toll, or are “reports of AI’s death greatly exaggerated”? We don’t see that in our data, though there are certainly some metrics to say that artificial intelligence has stalled. Many projects never make it to production, and while the last year has seen amazing progress in natural language processing (up 21%), such as OpenAI’s GPT-3, we’re seeing fewer spectacular results like winning Go games. It’s possible that AI (along with machine learning, data, big data, and all their fellow travelers) is descending into the trough of the hype cycle. We don’t think so, but we’re prepared to be wrong. As Ben Lorica has said (in conversation), many years of work will be needed to bring current research into commercial products.
It’s certainly true that there’s been a (deserved) backlash over heavy handed use of AI. A backlash is only to be expected when deep learning applications are used to justify arresting the wrong people, and when some police departments are comfortable using software with a 98% false positive rate. A backlash is only to be expected when software systems designed to maximize “engagement” end up spreading misinformation and conspiracy theories. A backlash is only to be expected when software developers don’t take into account issues of power and abuse. And a backlash is only to be expected when too many executives see AI as a “magic sauce” that will turn their organization around without pain or, frankly, a whole lot of work.
But we don’t think those issues, as important as they are, say a lot about the future of AI. The future of AI is less about breathtaking breakthroughs and creepy face or voice recognition than it is about small, mundane applications. Think quality control in a factory; think intelligent search on O’Reilly online learning; think optimizing data compression; think tracking progress on a construction site. I’ve seen too many articles saying that AI hasn’t helped in the struggle against COVID, as if someone was going to click a button on their MacBook and a superdrug was going to pop out of a USB-C port. (And AI has played a huge role in COVID vaccine development.) AI is playing an important supporting role—and that’s exactly the role we should expect. It’s enabling researchers to navigate tens of thousands of research papers and reports, design drugs and engineer genes that might work, and analyze millions of health records. Without automating these tasks, getting to the end of the pandemic will be impossible.
So here’s the future we see for AI and machine learning:
- Natural language has been (and will continue to be) a big deal. GPT-3 has changed the world. We’ll see AI being used to create “fake news,” and we’ll find that AI gives us the best tools for detecting what’s fake and what isn’t.
- Many companies are placing significant bets on using AI to automate customer service. We’ve made great strides in our ability to synthesize speech, generate realistic answers, and search for solutions.
- We’ll see lots of tiny, embedded AI systems in everything from medical sensors to appliances to factory floors. Anyone interested in the future of technology should watch Pete Warden’s work on TinyML very carefully.
- We still haven’t faced squarely the issue of user interfaces for collaboration between humans and AI. We don’t want AI oracles that just replace human errors with machine-generated errors at scale; we want the ability to collaborate with AI to produce results better than either humans or machines could alone. Researchers are starting to catch on.
TensorFlow is the leader among machine learning platforms; it gets the most searches, while usage has stabilized at 6% growth. Content about scikit-learn, Python’s machine learning library, is used almost as heavily, with 11% year-over-year growth. PyTorch is in third place (yes, this is a horse race), but usage of PyTorch content has gone up 159% year over year. That increase is no doubt influenced by the popularity of Jeremy Howard’s Practical Deep Learning for Coders course and the PyTorch-based fastai library (no data for 2019). It also appears that PyTorch is more popular among researchers, while TensorFlow remains dominant in production. But as Jeremy’s students move into industry, and as researchers migrate toward production positions, we expect to see the balance between PyTorch and TensorFlow shift.
Kafka is a crucial tool for building data pipelines; it’s stable, with 6% growth and usage similar to Spark. Pulsar, Kafka’s “next generation” competition, isn’t yet on the map.
Tools for automating AI and machine learning development (IBM’s AutoAI, Google’s Cloud AutoML, Microsoft’s AutoML, and Amazon’s SageMaker) have gotten a lot of press attention in the past year, but we don’t see any signs that they’re making a significant dent in the market. That content usage is nonexistent isn’t a surprise; O’Reilly members can’t use content that doesn’t exist. But our members aren’t searching for these topics either. It may be that AutoAI is relatively new or that users don’t think they need to search for supplementary training material.
What about data science? The report What Is Data Science is a decade old, but surprisingly for a 10-year-old paper, views are up 142% over 2019. The tooling has changed though. Hadoop was at the center of the data science world a decade ago. It’s still around, but now it’s a legacy system, with a 23% decline since 2019. Spark is now the dominant data platform, and it’s certainly the tool engineers want to learn about: usage of Spark content is about three times that of Hadoop. But even Spark is down 11% since last year. Ray, a newcomer that promises to make it easier to build distributed applications, doesn’t yet show usage to match Spark (or even Hadoop), but it does show 189% growth. And there are other tools on the horizon: Dask is newer than Ray, and has seen nearly 400% growth.
It’s been exciting to watch the discussion of data ethics and activism in the past year. Broader societal movements (such as #BlackLivesMatter), along with increased industry awareness of diversity and inclusion, have made it more difficult to ignore issues like fairness, power, and transparency. What’s sad is that our data shows little evidence that this is more than a discussion. Usage of general content (not specific to AI and ML) about diversity and inclusion is up significantly (87%), but the absolute numbers are still small. Topics like ethics, fairness, transparency, and explainability don’t make a dent in our data. That may be because few books have been published and few training courses have been offered—but that’s a problem in itself.
Web Development
Since the invention of HTML in the early 1990s, the first web servers, and the first browsers, the web has exploded (or degenerated) into a proliferation of platforms. Those platforms make web development infinitely more flexible: They make it possible to support a host of devices and screen sizes. They make it possible to build sophisticated applications that run in the browser. And with every new year, “desktop” applications look more old-fashioned.
So what does the world of web frameworks look like? React leads in usage of content and also shows significant growth (34% year over year). Despite rumors that Angular is fading, it’s the #2 platform, with 10% growth. And usage of content about the server-side platform Node.js is just behind Angular, with 15% growth. None of this is surprising.
It’s more surprising that Ruby on Rails shows extremely strong growth (77% year over year) after several years of moderate, stable performance. Likewise, Django (which appeared at roughly the same time as Rails) shows both heavy usage and 63% growth. You might wonder whether this growth holds for all older platforms; it doesn’t. Usage of content about PHP is relatively low and declining (8% drop), even though it’s still used by almost 80% of all websites. (It will be interesting to see how PHP 8 changes the picture.) And while jQuery shows healthy 18% growth, usage of jQuery content was lower than any other platform we looked at. (Keep in mind, though, that there are literally thousands of web platforms. A complete study would be either heroic or foolish. Or both.)
Vue and Flask make surprisingly weak showings: for both platforms, content usage is about one-eighth of React’s. Usage of Vue-related content declined 13% in the past year, while Flask grew 10%. Neither is challenging the dominant players. It’s tempting to think of Flask and Vue as “new” platforms, but they were released in 2010 and 2014, respectively; they’ve had time to establish themselves. Two of the most promising new platforms, Svelte and Next.js, don’t yet produce enough data to chart—possibly because there isn’t yet much content to use. Likewise, WebAssembly (Wasm) doesn’t show up. (It’s also too new, with little content or training material available.) But WebAssembly represents a major rethinking of web programming and bears watching closely. Could WebAssembly turn JavaScript’s dominance of web development on its head? We suspect that nothing will happen quickly. Enterprise customers will be reluctant to bear the cost of moving from an older framework like PHP to a more fashionable JavaScript framework. It costs little to stick with an old stalwart.
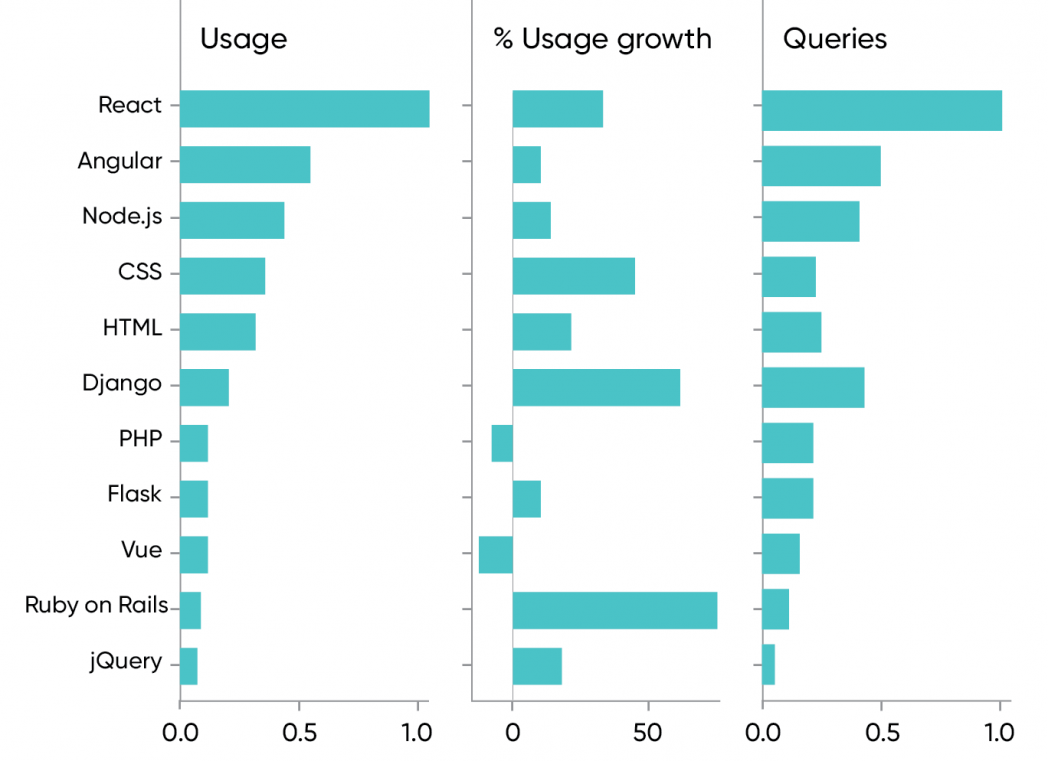
The foundational technologies HTML, CSS, and JavaScript are all showing healthy growth in usage (22%, 46%, and 40%, respectively), though they’re behind the leading frameworks. We’ve already noted that JavaScript is one of the top programming languages—and the modern web platforms are nothing if not the apotheosis of JavaScript. We find that chilling. The original vision for the World Wide Web was radically empowering and democratizing. You didn’t need to be a techno-geek; you didn’t even need to program—you could just click “view source” in the browser and copy bits you liked from other sites. Twenty-five years later, that’s no longer true: you can still “view source,” but all you’ll see is a lot of incomprehensible JavaScript. Ironically, just as other technologies are democratizing, web development is increasingly the domain of programmers. Will that trend be reversed by a new generation of platforms, or by a reformulation of the web itself? We shall see.
Clouds of All Kinds
It’s no surprise that the cloud is growing rapidly. Usage of content about the cloud is up 41% since last year. Usage of cloud titles that don’t mention a specific vendor (e.g., Amazon Web Services, Microsoft Azure, or Google Cloud) grew at an even faster rate (46%). Our customers don’t see the cloud through the lens of any single platform. We’re only at the beginning of cloud adoption; while most companies are using cloud services in some form, and many have moved significant business-critical applications and datasets to the cloud, we have a long way to go. If there’s one technology trend you need to be on top of, this is it.
The horse race between the leading cloud vendors, AWS, Azure, and Google Cloud, doesn’t present any surprises. Amazon is winning, even ahead of the generic “cloud”—but Microsoft and Google are catching up, and Amazon’s growth has stalled (only 5%). Use of content about Azure shows 136% growth—more than any of the competitors—while Google Cloud’s 84% growth is hardly shabby. When you dominate a market the way AWS dominates the cloud, there’s nowhere to go but down. But with the growth that Azure and Google Cloud are showing, Amazon’s dominance could be short-lived.
What’s behind this story? Microsoft has done an excellent job of reinventing itself as a cloud company. In the past decade, it’s rethought every aspect of its business: Microsoft has become a leader in open source; it owns GitHub; it owns LinkedIn. It’s hard to think of any corporate transformation so radical. This clearly isn’t the Microsoft that declared Linux a “cancer,” and that Microsoft could never have succeeded with Azure.
Google faces a different set of problems. Twelve years ago, the company arguably delivered serverless with App Engine. It open sourced Kubernetes and bet very heavily on its leadership in AI, with the leading AI platform TensorFlow highly optimized to run on Google hardware. So why is it in third place? Google’s problem hasn’t been its ability to deliver leading-edge technology but rather its ability to reach customers—a problem that Thomas Kurian, Google Cloud’s CEO, is attempting to address. Ironically, part of Google’s customer problem is its focus on engineering to the detriment of the customers themselves. Any number of people have told us that they stay away from Google because they’re too likely to say, “Oh, that service you rely on? We’re shutting it down; we have a better solution.” Amazon and Microsoft don’t do that; they understand that a cloud provider has to support legacy software, and that all software is legacy the moment it’s released.
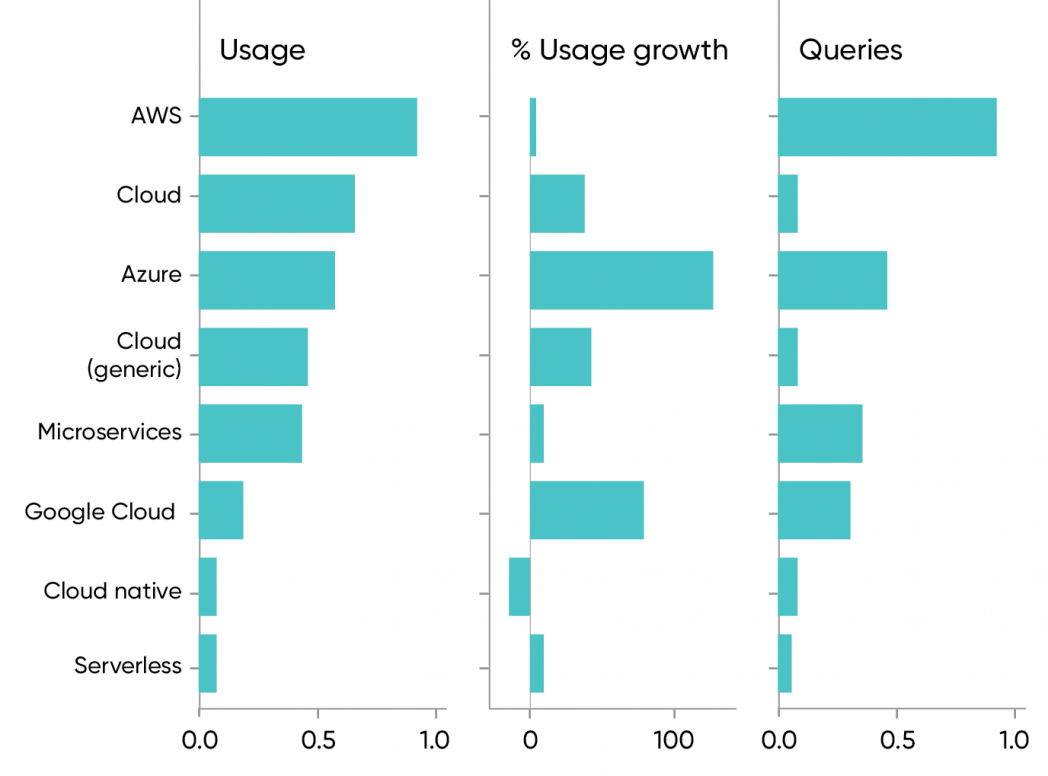
While our data shows very strong growth (41%) in usage for content about the cloud, it doesn’t show significant usage for terms like “multicloud” and “hybrid cloud” or for specific hybrid cloud products like Google’s Anthos or Microsoft’s Azure Arc. These are new products, for which little content exists, so low usage isn’t surprising. But the usage of specific cloud technologies isn’t that important in this context; what’s more important is that usage of all the cloud platforms is growing, particularly content that isn’t tied to any vendor. We also see that our corporate clients are using content that spans all the cloud vendors; it’s difficult to find anyone who’s looking at a single vendor.
Not long ago, we were skeptical about hybrid and multicloud. It’s easy to assume that these concepts are pipe dreams springing from the minds of vendors who are in second, third, fourth, or fifth place: if you can’t win customers from Amazon, at least you can get a slice of their business. That story isn’t compelling—but it’s also the wrong story to tell. Cloud computing is hybrid by nature. Think about how companies “get into the cloud.” It’s often a chaotic grassroots process rather than a carefully planned strategy. An engineer can’t get the resources for some project, so they create an AWS account, billed to the company credit card. Then someone in another group runs into the same problem, but goes with Azure. Next there’s an acquisition, and the new company has built its infrastructure on Google Cloud. And there’s petabytes of data on-premises, and that data is subject to regulatory requirements that make it difficult to move. The result? Companies have hybrid clouds long before anyone at the C-level perceives the need for a coherent cloud strategy. By the time the C suite is building a master plan, there are already mission-critical apps in marketing, sales, and product development. And the one way to fail is to dictate that “we’ve decided to unify on cloud X.”
All the cloud vendors, including Amazon (which until recently didn’t even allow its partners to use the word multicloud), are being drawn to a strategy based not on locking customers into a specific cloud but on facilitating management of a hybrid cloud, and all offer tools to support hybrid cloud development. They know that support for hybrid clouds is key to cloud adoption–and, if there is any lock in, it will be around management. As IBM’s Rob Thomas has frequently said, “Cloud is a capability, not a location.”
As expected, we see a lot of interest in microservices, with a 10% year-over-year increase—not large, but still healthy. Serverless (a.k.a. functions as a service) also shows a 10% increase, but with lower usage. That’s important: while it “feels like” serverless adoption has stalled, our data suggests that it’s growing in parallel with microservices.
Security and Privacy
Security has always been a problematic discipline: defenders have to get thousands of things right, while an attacker only has to discover one mistake. And that mistake might have been made by a careless user rather than someone on the IT staff. On top of that, companies have often underinvested in security: when the best sign of success is that “nothing bad happened,” it’s very difficult to say whether money was well spent. Was the team successful or just lucky?
Yet the last decade has been full of high-profile break-ins that have cost billions of dollars (including increasingly hefty penalties) and led to the resignations and firings of C-suite executives. Have companies learned their lessons?
The data doesn’t tell a clear story. While we’ve avoided discussing absolute usage, usage of content about security is very high—higher than for any other topic except for the major programming languages like Java and Python. Perhaps a better comparison would be to compare security with a general topic like programming or cloud. If we take that approach, programming usage is heavier than security, and security is only slightly behind cloud. So the usage of content about security is high, indeed, with year-over-year growth of 35%.
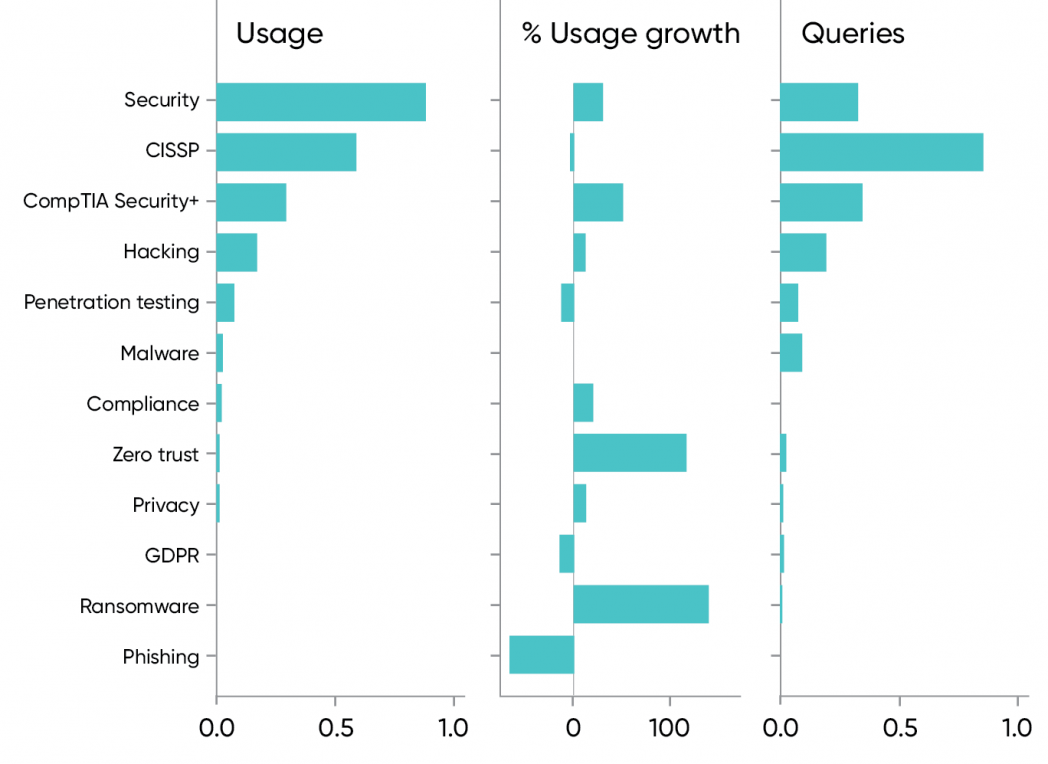
But what content are people using? Certification resources, certainly: CISSP content and training is 66% of general security content, with a slight (2%) decrease since 2019. Usage of content about the CompTIA Security+ certification is about 33% of general security, with a strong 58% increase.
There’s a fair amount of interest in hacking, which shows 16% growth. Interestingly, ethical hacking (a subset of hacking) shows about half as much usage as hacking, with 33% growth. So we’re evenly split between good and bad actors, but the good guys are increasing more rapidly. Penetration testing, which should be considered a kind of ethical hacking, shows a 14% decrease; this shift may only reflect which term is more popular.
Beyond those categories, we get into the long tail: there’s only minimal usage of content about specific topics like phishing and ransomware, though ransomware shows a huge year-over-year increase (155%); that increase no doubt reflects the frequency and severity of ransomware attacks in the past year. There’s also a 130% increase in content about “zero trust,” a technology used to build defensible networks—though again, usage is small.
It’s disappointing that we see so little interest in content about privacy, including content about specific regulatory requirements such as GDPR. We don’t see heavy usage; we don’t see growth; we don’t even see significant numbers of search queries. This doesn’t bode well.
Not the End of the Story
We’ve taken a tour through a significant portion of the technology landscape. We’ve reported on the horse races along with the deeper stories underlying those races. Trends aren’t just the latest fashions; they’re also long-term processes. Containerization goes back to Unix version 7 in 1979; and didn’t Sun Microsystems invent the cloud in the 1990s with its workstations and Sun Ray terminals? We may talk about “internet time,” but the most important trends span decades, not months or years—and often involve reinventing technology that was useful but forgotten, or technology that surfaced before its time.
With that in mind, let’s take several steps back and think about the big picture. How are we going to harness the computing power needed for AI applications? We’ve talked about concurrency for decades, but it was only an exotic capability important for huge number-crunching tasks. That’s no longer true; we’ve run out of Moore’s law, and concurrency is table stakes. We’ve talked about system administration for decades, and during that time, the ratio of IT staff to computers managed has gone from many-to-one (one mainframe, many operators) to one-to-thousands (monitoring infrastructure in the cloud). As part of that evolution, automation has also gone from an option to a necessity.
We’ve all heard that “everyone should learn to program.” This may be correct…or maybe not. It doesn’t mean that everyone should be a professional programmer but that everyone should be able to use computers effectively, and that requires programming. Will that be true in the future? No-code and low-code products are reaching the market, allowing users to build everything from business applications to AI prototypes. Again, this trend goes way back: in the late 1950s, the first modern programming languages made programming much easier. And yes, even back then there were those who said “real men use machine language.” (And that sexism was no doubt intentional, since the first generation of programmers included many women.) Will our future bring further democratization? Or a return to a cult of “wizards”? Low-code AI and complex JavaScript web platforms offer conflicting visions of what the future may bring.
Finally, the most important trend may not yet appear in our data at all. Technology has largely gotten a free ride as far as regulation and legislation are concerned. Yes, there are heavily regulated sectors like healthcare and finance, but social media, much of machine learning, and even much of online commerce have only been lightly regulated. That free ride is coming to an end. Between GDPR, the California Consumer Privacy Act (which will probably be copied by many states), California Propositions 22 and 24, many city ordinances regarding the use of face recognition, and rethinking the meaning of Section 230 of the Communications Decency Act, laws and regulations will play a big role in shaping technology in the coming years. Some of that regulation was inevitable, but a lot of it is a direct response to an industry that moved too fast and broke too many things. In this light, the lack of interest in privacy and related topics is unhealthy. Twenty years ago, we built a future that we don’t really want to live in. The question facing us now is simple:
What future will we build?
Source of Article



