Commentary: Timescale has a novel licensing model that it hopes will be “open enough” to create a community. Will it work?

Image: Getty Images/iStockphoto
For decades developers would build applications using the same database tools. They might opt for Oracle over IBM’s DB2, or for an open source database like MySQL or PostgreSQL, but they were nearly always all using a relational database, speaking SQL.
My, how times have changed.
Today developers have a smorgasbord of options from which to choose, whether document or key-value or columnar or relational or multi-model. But over the past two years, no database category has seen more growth than time series databases, something evident a year ago but now glaring in its obviousness. When I asked Timescale CEO Ajay Kulkarni why this once niche, now prevalent approach has gained in popularity, he explained it as a matter of data fidelity: “Time series is the highest fidelity of data that you can capture because it tells you exactly how things are changing over time.”
What is less obvious is how to monetize an open source database. For this, Kulkarni has some new ideas. Let’s look at them.
SEE: Special report: Prepare for serverless computing (free PDF) (TechRepublic)
A cornucopia of database options
As tiresome as it may have been to hit the data nail with a relational database hammer for so long, today developers have an opposite problem: There are so many options. Perhaps too many. (DB-Engines lists 359 different databases.)
Over the past two years, time series databases have exploded in popularity, relative to other options (Figure A).
Figure A
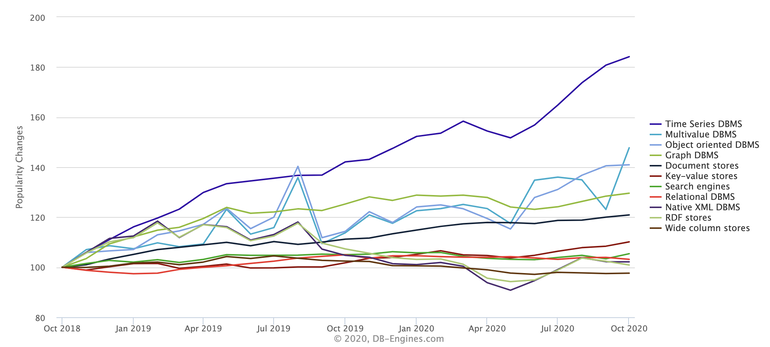
Image: DB-Engines
According to Kulkarni, as “data has exploded and is playing a more and more critical role, you want the best tool for the job.” This has led to the rise in purpose-built databases. The analogy Kulkarni used is shoes. There was a time that you’d make do with “trainers” that you might use for cycling, basketball, etc., but today, if you’re a serious road cyclist, you have special shoes for that. Different ones for mountain biking. Still different shoes for running (trail? road?), basketball, etc. For a serious athlete, you’re going to optimize your shoes for the activity. Similarly, he said, “If you have a time series workload that is mission critical for your business, why would you use something that wasn’t built for that?”
But how, I asked Kulkarni, are developers figuring out when to use a time series database?
Developers will tend to recognize that they have a time series problem, he said. Anytime you need to understand how something changes over time, you have a time series application. A time series database “gives you a dynamic view of what’s happening across your system,” he noted, with that “system” being a software system, a physical power plant, a game, etc. Tracking how data changes over time can yield huge volumes and velocity of data, which other database types might struggle to tackle. By contrast, he stressed, “time series databases like TimescaleDB optimize for these workloads in a way that allows you to get orders of magnitude better performance and scalability at a fraction of the cost.”
Given the increasing attention that developers are paying to open source time series databases like TimescaleDB, InfluxDB, and others, the question for Kulkarni has become one of ensuring his company can capitalize by turning this interest into revenue which, in turn, can fund more investment and innovation. The key for TimescaleDB has been to figure out how to retain the benefits of open source (e.g., community) without sacrificing the company’s ability to fund operations.
Source available, community ready
Timescale has long relied on an open core business model, wherein the company offered the bulk of its code under an open source license (Apache 2.0), making other, advanced components available under a proprietary license. Though open core has been a common model for commercial open source, it has plenty of problems (which I and others have called out). One primary problem is that it blocks community from those advanced features, and community, more than anything else, is what fuels open source adoption.
So Timescale put a new spin on open core: It made 100% of its code source available. That Apache 2.0-licensed core would remain under this license. But the advanced functionality will now be available under a source available license that allows for developers to do pretty much anything they might want, except build a competing database-as-a-service offering. (However, anyone can build a cloud service from the Apache 2.0-licensed core, which DigitalOcean and others have.)
Is it open source? No, it’s not. Will that matter? Kulkarni believes that Timescale’s approach is open in essential ways that will allow Timescale’s community to flourish:
As developers, we like to inspect the code we’re using. Even if we don’t [actually look at source code], we’d like the ability to do it….[A]s a company,…we like the public open source development process. It’s like the things you see in GitHub. It’s public issues, public [pull requests], public commentary. People can see things on the open. And so the goal of our Timescale license was to make the proprietary stuff more open, make it more like open source so that we can work more closely with our community out in the open. Another advantage of having a single code base is that it allows us to develop new features faster instead of having to invest energy in keeping two different repos and stuff.
It’s hard to know exactly The Right Thing To Do™ with an open source business these days as cloud and open source co-mingle. FaunaDB has eschewed open source altogether, relying instead on the richness of its data API to entice developers. Chef and Yugabyte both dropped open core in favor of 100% open source approaches. RackN, on the other hand, decided to make its core proprietary, and open sourced the rest. Companies are experimenting.
But couldn’t Timescale simply open source everything under Apache 2.0 and compete on the basis of offering superior operation of that software, I asked? Sure, said Kulkarni, “We’ll be better operators of TimescaleDB than…anyone else ever will, for a variety of reasons. We know the code base, we can write patches and updates faster than anyone else,” etc. And yet the cloud providers have other advantages that make it a competitive mismatch, he concluded.
It will be fascinating to see how this plays out. The popularity of time series databases like TimescaleDB isn’t in question. The popularity of Timescale’s business model remains to be seen. Has the company reserved enough of the benefits of open source in its source available license to capture the convenience and community of open source? Time (no pun intended) will tell.
Disclosure: I work for AWS, but the views herein are mine and not those of my employer.

Open Source Weekly Newsletter
You don’t want to miss our tips, tutorials, and commentary on the Linux OS and open source applications. Delivered Tuesdays
Also see
Source of Article



